





As more and more organizations experiment with Generative AI and deploy it in production, a crucial question emerges: Can these applications be both safe and scalable in an enterprise context? The answer is yes, via the LLM Mesh — a common backbone for Generative AI applications that promises to reshape how analytics and IT teams securely access Generative AI models and services.
The LLM Mesh enables organizations to efficiently build enterprise-grade applications while addressing concerns related to cost management, compliance, and technological dependencies. It also enables choice and flexibility among the growing number of models and providers.
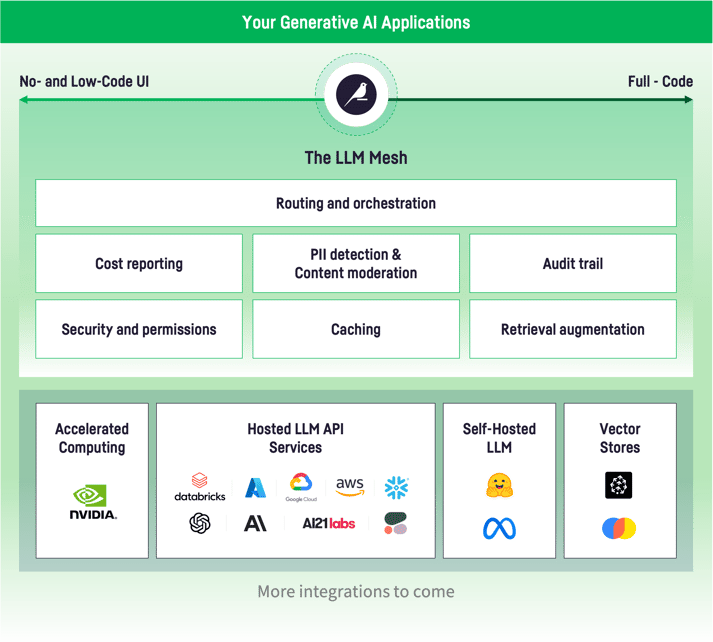
We’re thrilled to be joined by our LLM Mesh Launch Partners Snowflake, NVIDIA, Pinecone, and AI21 Labs as we address the critical need for an effective, scalable, and secure platform for integrating LLMs in the enterprise. The full list of Dataiku’s LLM Mesh integrations include:
Hosted LLM API Services:
- Snowflake
- AI21 Labs
- Azure OpenAI Service
- Google Vertex AI
- AWS Bedrock
- OpenAI
- Anthropic
- Cohere
- MosaicML
Self-Hosted Private LLM:
- Hugging Face (Llama2, Falcon, Dolly 2, MPT, and other fully-private LLMs)
Vector Stores:
- Pinecone
- FAISS
- ChromaDB
Accelerated Computing:
- NVIDIA
This article summarizes core challenges that the LLM Mesh answers (namely, managing safety, performance, and cost), the main benefits organizations can drive by leveraging it, and how Dataiku enables organizations to build and deploy enterprise-grade Generative AI applications via the LLM Mesh.
Overcome Generative AI Roadblocks With the LLM Mesh
To build Generative AI applications that generate both short-term and sustained value, analytics and IT teams need to surpass several key challenges. The LLM Mesh was designed to address:
Choice and Dependency: Application builders have a growing choice of models from different providers at their disposal. This is a good thing: Different models and providers allow organizations to choose a model and service that best suits the cost, performance, and security needs of a given application. Given the fast-moving landscape, teams will benefit from keeping their choices open versus falling victim to lock in. However, if the application is "hardwired" to the underlying model or service, this makes testing different models difficult in the design phase and creates a dependency that can be difficult and expensive to break once the application is deployed into production.
Cost: Creating and running LLMs is expensive, and providers naturally pass that cost along via API fees. So, failure to properly manage requests, especially for repeated prompts, could result in sizable unforeseen costs and a severe black eye for IT Operations. While data teams will evaluate the performance of LLMs based on accuracy, IT has to focus on latency and SLAs.
Privacy, Security, & Compliance: Users of LLM applications create prompts that may convey sensitive corporate IP or PII. This data leakage could result in loss of revenue, significant fines (from regulators) or a PR disaster, should such data appear in the public domain. Further, new AI regulations, like the EU AI Act, will require companies using LLMs to show where they are using the technology, who has access to the technology, and to prove they are limiting the risk to consumers or face significant fines. Finally, responses from LLMs may contain inappropriate or even offensive content (known as toxicity). Allowing employees or, even worse, customers to view this content could seriously impact your business from a customer relationship, legal, and PR perspective.
Benefits of the LLM Mesh
With the LLM Mesh sitting between LLM service providers and end-user applications, companies have the agility to choose the most cost-effective models for their needs, ensure the safety of their data and responses, and create reusable components for scalable application development. Let’s dive a bit deeper into some of these key advantages:
1. Decoupling Application From Service Layer
It is not always immediately clear which LLM is going to provide the best output for the application that a team is attempting to build. They need to balance cost, security, performance, and speed. First, in the design phase, they need to be able to efficiently test different models to determine which will work best. Then, they need to maintain the ability to change once the application is deployed. This decoupling of the application and AI service layers makes it possible to design the best possible applications, and then maintain them easily in production.
2. Enforcing a Secure Gateway
Standard IT practices dictate that organizations need to maintain a complete trail of the queries run against their infrastructure. This is both to manage performance (i.e. identifying the culprit behind that inefficient join) and to ensure security (i.e. knowing who is querying which data and for which reasons). The same needs translate over to LLMs.
The LLM Mesh acts as a secure API gateway to break down hard-coded dependencies and manage and route requests between applications and underlying services. A fully auditable log of who is using which LLM and which service for which purpose allows for both cost tracking (and internal re-billing), as well as the full traceability of both requests and responses to these sometimes unpredictable models.
3. Security, Permissions, & PII
When it comes to screening for private data, the LLM Mesh evaluates each request for sensitive information, like confidential or proprietary data, or customer PII. The system then takes an appropriate action: redact this sensitive information before sending the request to the LLM API, block the request entirely, and/or alert an admin. Multiple forms of PII detection co-exist, by using standard PII detection models, by leveraging internal databases or by using third-party services that provide advanced capabilities or industry-specific knowledge.
Next, to reduce the risk of business users making ungoverned requests to public chatbots, companies can use paid LLM services with secure access. These services, such as from OpenAI, Azure, and Google, do not capture request information for model training. The LLM Mesh provides central access to AI services, including safeguarding API keys, which allows for controlled access to LLM services and streamlines application development and maintenance because keys are not hardcoded into applications.
4. Cost & Performance Control
The LLM Mesh monitors cost per query to LLMs and aggregates costs by application and service. This allows teams to forecast costs and make informed decisions about service usage.
For performance monitoring, the LLM Mesh monitors the round-trip performance for LLM services and providers so teams can diagnose issues and select the optimal service based on application needs and SLAs. Additionally, caching of responses to common queries avoids the need to regenerate the response, offering both cost savings and a performance boost.
5. Retrieval-Augmented Generation and Vector Databases
The LLM Mesh includes standard application development components and capabilities for use across multiple applications — for example, Retrieval Augmented Generation (RAG). RAG is becoming a standard way to infuse your internal company knowledge into the responses of an LLM.
RAG works by indexing your internal knowledge (such as your product catalog, your support knowledge base, etc.) into a specialized data structure called a Vector Store. At query time, the Vector Store searches for the most appropriate pieces of content based on the user query, and injects it in the prompt that is submitted to the LLM, ensuring the LLM can generate an answer that takes your internal knowledge into account. The LLM Mesh provides integration with Vector Stores and implements the whole RAG pattern with no code needed.
What Role Does Dataiku Play?
Dataiku is the pioneer of the LLM Mesh and Dataiku’s platform provides the functionality needed to build and deploy Generative AI applications in the most stringent enterprise environments. Importantly, these new LLM-specific capabilities are not add-ons to our platform, but are deeply integrated into the core capabilities that we have built over the past decade: data connections and security, data preparation and pipelines, data science and ML, ops and governance. And, as ever, it is accessible all in a collaborative, multi-profile environment offering low- and no-code UIs, as well as a full-code experience for developers.
The LLM Mesh, as outlined above, is the holistic solution to the challenges blocking today’s organizations from harnessing Generative AI safely and at scale. As the pioneer in LLM Mesh, Dataiku has already delivered critical components for enterprise LLM application development. This includes:
- Prompt Studios for prompt engineering
- Native LLM application development recipes
- Native RAG support
- Partnerships with leading providers of LLMs, vector databases, accelerated compute capabilities, and containerized compute capabilities
Just as Dataiku has created the common standard for analytics and ML in the enterprise, the introduction of the LLM Mesh will become the standard for Generative AI in the enterprise. As my co-founder (and Dataiku’s CEO) said two weeks ago: We were built for this moment. Here’s to the next ten years.